The Vectorized Cluster Buffer (VCB)
Solving Catastrophic Forgetting in High-Throughput Robotics Training
Abstract
The Vectorized Cluster Buffer (VCB) is a high-performance memory architecture designed specifically for the unique demands of modern robotics. By integrating continuous, real-time experience clustering with a hardware-aligned data pipeline, the VCB ensures that rare but critical "life experiences" are preserved during training. This architecture effectively mitigates catastrophic forgetting, allowing Dojo to achieve unprecedented training stability without sacrificing the raw throughput required for complex sim-to-real workflows.
Architectural Overview
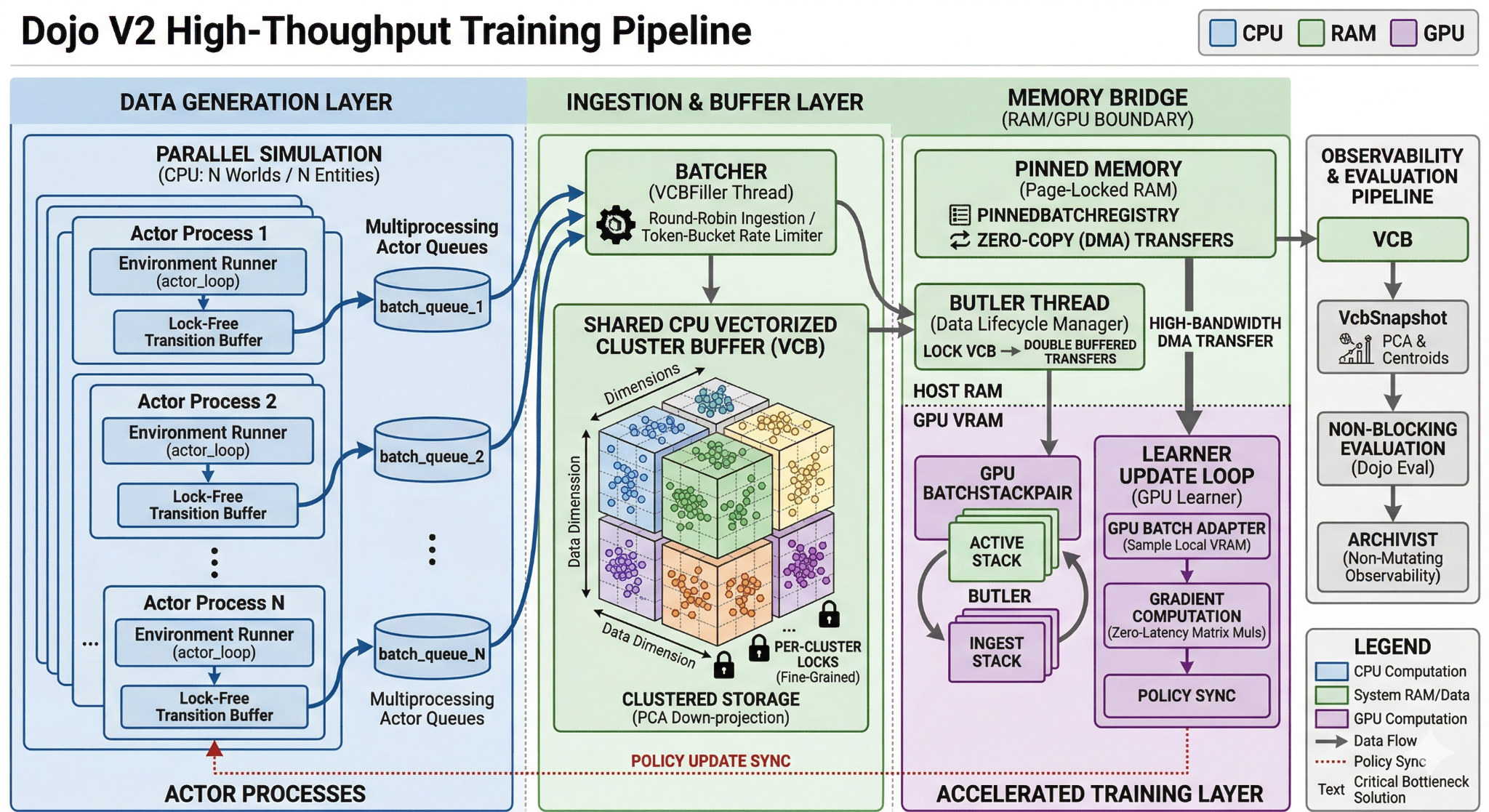
At the heart of the Dojo platform, the VCB acts as a sophisticated bridge between the chaotic, asynchronous world of mass-parallel simulation and the structured, latency-sensitive world of GPU-bound learning.
Unlike standard training buffers that treat experience as a uniform stream, the VCB treats experience as a structured distribution.
Memory Management and Data Locality
The VCB operates as the Clustered Memory Engine, explicitly partitioned to optimize how data moves from the CPU to the GPU. This design is focused on maximizing "Learning Density"—ensuring that every byte of data transferred across the PCIe bus contains the maximum possible information for the model.
- Pinned Memory Registry: To prevent the GPU from waiting for data, the system uses a Pinned Memory Bridge. This allows the GPU to pull training batches via Direct Memory Access (DMA), effectively hiding the cost of data movement behind active computation.
- Hardware-Optimized Layout: Experience transitions are structured in contiguous, typed memory blocks. This prevents the "pointer-chasing" delays common in generic frameworks and ensures that the CPU can prepare training data at the same speed the GPU consumes it.
The Ingest Coordinator: Semantic Experience Routing
The distinguishing feature of the VCB is how it routes new experiences. As data flows in from hundreds of parallel simulations, the Ingest Coordinator analyzes the latent characteristics of each transition.
Rather than simply stacking data in a first-in, first-out queue, the system performs real-time Principal Component Analysis (PCA) and KMeans clustering. This allows the VCB to identify where a new experience "fits" within the model's existing knowledge base.
If the model encounters a rare recovery maneuver or a near-failure state, the VCB recognizes its semantic value and routes it to a specific cluster. This ensures that these "Golden Transitions" are not immediately overwritten by the flood of common, successful trajectories.
Training Advantages: Homogeneous Diversity
The VCB provides profound advantages for modern reinforcement learning:
- Homogeneous Batching: By sampling uniformly across all semantic clusters for every training batch, the VCB guarantees that the model is always exposed to a diverse slice of the entire state space. This prevents the "performance collapse" that occurs when a model over-optimizes for its most recent—but often repetitive—successes.
- Zero-Latency Resumption: Because the VCB maintains a structured snapshot of the training distribution, researchers can pause and resume training instantly. The model doesn't have to "re-learn" the state space; it can pick up exactly where it left off with a mature memory buffer already in place.
Empirical Results: Proving Long-Tail Retention
To validate the impact of the VCB, we compared a standard uniform replay buffer against a 128-cluster VCB configuration under identical high-throughput conditions (~200,000 samples per second).
Replay Age Distribution (The p95 Shift)
The most significant metric for stability is the 95th percentile (p95) age of the samples in the buffer. While the average age remains similar in both systems, the VCB shows a massive increase in how long it holds onto the "long tail" of experience.
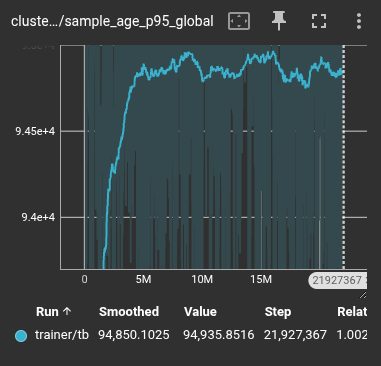
Standard Replay: Bounded age distribution leads to rapid forgetting.
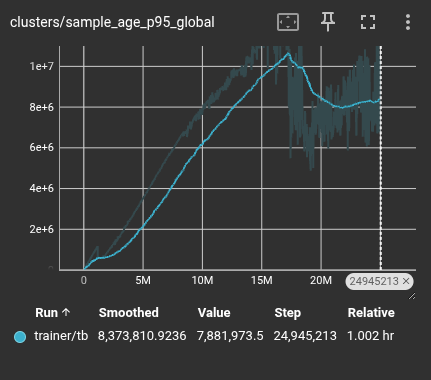
VCB: Significantly extended retention of historical "life experience."
| Retention Metric | Standard Buffer | Dojo VCB |
|---|---|---|
| Median Sample Age (p50) | 53,112 steps | 52,590 steps |
| Long-Tail Retention (p95) | 95,853 steps | 6,166,426 steps |
The VCB provides a two-order-of-magnitude increase in how long critical experiences remain available for training. This is the difference between a model that "forgets" its failures within seconds and one that carries those lessons for the duration of the mission.
Protecting Rare Events (Golden Transitions)
We tracked "Golden Transitions"—rare, high-value events tagged during collection—to see how long they survived in memory. In a standard buffer, these events decay almost immediately as new data floods in. In the VCB, they are pinned into clusters and resurfaced continuously.
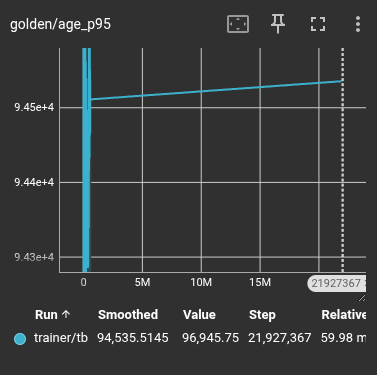
Standard: Rare events are lost in the noise of successful runs.
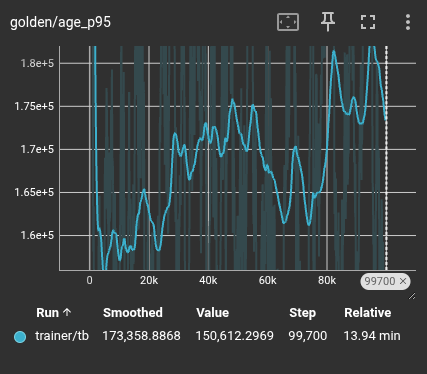
VCB: Rare events are preserved for over 12 million training steps.
Visualizing Structured Replay
The impact of the VCB is most visible in the Cluster Heatmap. In a standard single-cluster system, all experience collapses into a single, unstructured blob. In the 128-cluster VCB, we see the emergence of clear, vertical structure.
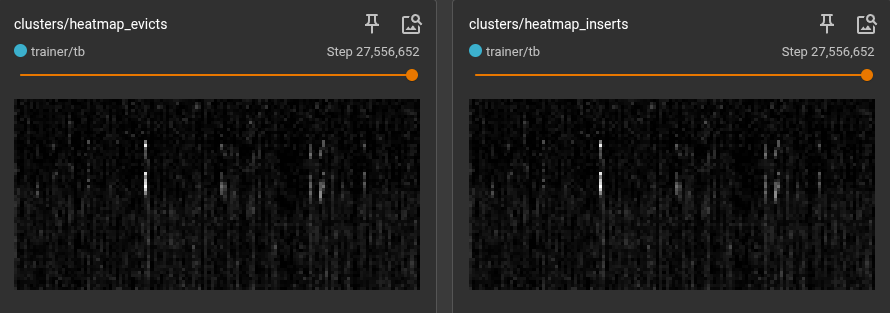
The Digital Fingerprint of Experience: Each column in the heatmap above represents one of the 128 VCB clusters.
The searing white lines represent "hot" clusters—the common, everyday experiences the robot encounters. The darker regions are the "cold" clusters—the rare edge cases, recoveries, and near-misses.
By forcing the training pipeline to sample from every cluster equally, Dojo ensures the model never "forgets" the dark regions of the state space, creating a controller that is as stable in failure as it is in success.